NOTE: Do not upload any image that violates our Picture Policy. Doing so will result in the removal of the concerned image without prior notification.
Crop Picture
Auto Cropped
Note:Microsoft Internet Explorer restricts the images to be uploaded one by one. To upload multiple images at the same time please use other browser.
Syed Abbas Zaidi
Machine Learning
Bharat Intern - Bhopal, India
خلاصہ
I am a Software Engineer. And I have done Bachelor of Science (BS) in Software Engineering from University of Sindh, Jamshoro in March 2019.I have one year experience in Support Software. I have worked as an Associate Consultant at Inserito PVT Ltd and as a Technical Support Assistant at Gentec Software House. I have completed a one-month Remote Internship as a Data Scientist at Oasis InfoByte & CodSoft and as a Python Developer at Code Alpha & OctaNet Software Services, and as a Data Analyst at MeriSKILL. I have recently completed a one-month Remote Internship as a Machine Learning at BharatIntern. I have Certifications in various fields and have gained valuable experience in Data analysis, Data Science & Machine Learning Projects.
پراجیکٹس
HR Analytics | Power BI
Diabetes Patients
Sales Data Analysis
Credit Card Fraud Detection USING PYTHON
Sales Prediction Using Python
IRIS Flower Classification
MOVIE RATING PREDICTION WITH PYTHON
TITANIC SURVIVAL PREDICTION
تجربہ
Machine Learning
Bharat Intern
نومبر ۲۰۲۳
- دسمبر ۲۰۲۳
| Bhopal, India
Machine Learning | Bharat Intern
Remote Internship | November – 2023 – December – 2023
In the Machine Learning Internship at Bharat Intern, I completed three projects.
Developed accurate ML models for House Price Predictions, Movie Recommendations, and Iris flower classification.
Explored, cleaned, and visualized diverse datasets.
Implemented Random Forest and Neural Network Models using Python, scikit-learn, and TensorFlow.
Created user-friendly Streamlit applications for real-world usability.
Gained in-depth insights into ML concepts and effective data exploration techniques.
Projects Link: https://github.com/IrtizaZaidi356/BharatIntern_Machine_Learni ng_Remote_Internship
Python Development
Code Alpha
نومبر ۲۰۲۳
- دسمبر ۲۰۲۳
| Lucknow, India
Python Development | Code Alpha
Remote Internship | November – 2023 – December – 2023
In the Python Development Internship at Code Alpha, I completed three projects.
Developed interactive Python projects: Hangman Game, URL Shortener, and Basic ChatBot.
Applied Tkinter for GUI, shortuuid for URL generation, and NLTK for NLP.
Strengthened Python skills in GUI development and NLP.
Demonstrated problem-solving abilities and adaptability.
Projects Link: https://github.com/IrtizaZaidi356/CodeAlpha_PythonIntern_Remo teInternship
Data Science
Oasis Infobyte
نومبر ۲۰۲۳
- دسمبر ۲۰۲۳
| New Delhi, India
Data Science | Oasis InfoByte
Remote Internship | November – 2023 – December – 2023
Data Science Internship at Oasis InfoByte focused on hands-on projects.
Developed predictive models for projects like IRIS Flower Classification, Unemployment Analysis, Car Price Prediction, Email Spam Detection, and Sales Prediction.
Proficient in Python, scikit-learn, and data visualization.
Developed ML models for classification and prediction.
Applied EDA techniques to gain insights into diverse datasets.
Enhanced user interaction for real-time predictions.
Projects Link: https://github.com/IrtizaZaidi356/OIBSIP
Python Developer
OctaNet Software Services.
نومبر ۲۰۲۳
- دسمبر ۲۰۲۳
| Bhubaneshwar, India
Python Develoer | OctaNet Software Services
Remote Internship | November – 2023 – December – 2023
In the Python Development Internship at OctaNet Software Services.
Developed a secure Python ATM System with user authentication and a user-friendly menu.
Implemented transparent financial tracking through transaction history.
Enabled error-free banking operations with robust input validation.
Contributed to a functional and secure system, providing essential services.
Established a foundation for future enhancements and realistic database integration.
Project Link: https://github.com/IrtizaZaidi356/OctaNetSW_PythonDevelopme nt_Remote_Internship
Data Analyst
MeriSKILL
اکتوبر ۲۰۲۳
- نومبر ۲۰۲۳
| New Delhi, India
Data Analyst | MeriSKILL | Remote Internship | October – 2023 – November – 2023
In the Data Analyst Internship at MeriSkill, I completed three projects.
The First Project involved Power BI Sales Data Analysis, which included extracting insights from extensive datasets, analyzing sales trends, identifying top-selling products, and creating an interactive dashboard.
The Second Project focused on Diabetes Prediction using Machine Learning (ML), utilizing Python libraries and a Random Forest Classifier Model for early diagnosis.
The Third Project, HR Analytics, combined data cleaning and visualization to enhance data integrity and support informed HR decisions, revealing trends in HR metrics.
These projects demonstrated my proficiency in data analysis, manipulation, and their application in healthcare and organizational decision-making.
Projects Link: https://github.com/IrtizaZaidi356/MeriSKILL_Internship_Projects
Data Science Internship
CodSoft
ستمبر ۲۰۲۳
- اکتوبر ۲۰۲۳
| Kolkata, India
Data Science | CodSoft | Remote Internship | September – 2023 – October – 2023
Data Science Internship at CodSoft focused on hands-on projects.
Developed predictive models for projects like Titanic survival and movie ratings, iris flower classification, sales prediction & Credit Card Fraud Detection.
Employed Python libraries, including Pandas, Numpy, Seaborn, Matplotlib, and Scikit-Learn.
Utilized Machine Learning (ML) techniques like Logistic Regression and Linear Regression.
Created data visualization graphics, translating complex data sets into comprehensive visual representations.
Identified, analyzed and interpreted trends in complex data sets using supervised and unsupervised learning techniques.
Successfully completed projects in data analysis, classification, and predictive modeling.
Projects Link: https://github.com/IrtizaZaidi356/CODSOFT
Assistant Technical Support
Gentec Software House
نومبر ۲۰۲۰
- مارچ ۲۰۲۱
| Karachi, Pakistan
Major responsibilities include getting requirements from the user, writing stored procedures for reports and developing reports using Crystal Reports 2008. Maintaining proper documentation of the reports for future reference.
Involved in writing stored procedures to get data from database.
Developed unlinked, on-demand sub reports and linked sub reports using shared variables and complex reports like cross-tab reports.
Developed complex reusable formula, parameter reports and reports with advanced features such as conditional formatting, built-in/custom functions and stored them in repository explorer.
Exported reports from crystal to excel.
NetSuite ERP - Associate Consultant
Inserito Pvt
نومبر ۲۰۱۹
- اگست ۲۰۲۰
| Karachi, Pakistan
Responsible for identifying business requirements, functional design, process design, testing, training, defining support procedures, leading and supporting NetSuite implementations.
Provide administration and customization solutions to NetSuite customers.
Provide recommendation on client’s process and workflow relative to CRM, Administration and Suitebuilder.
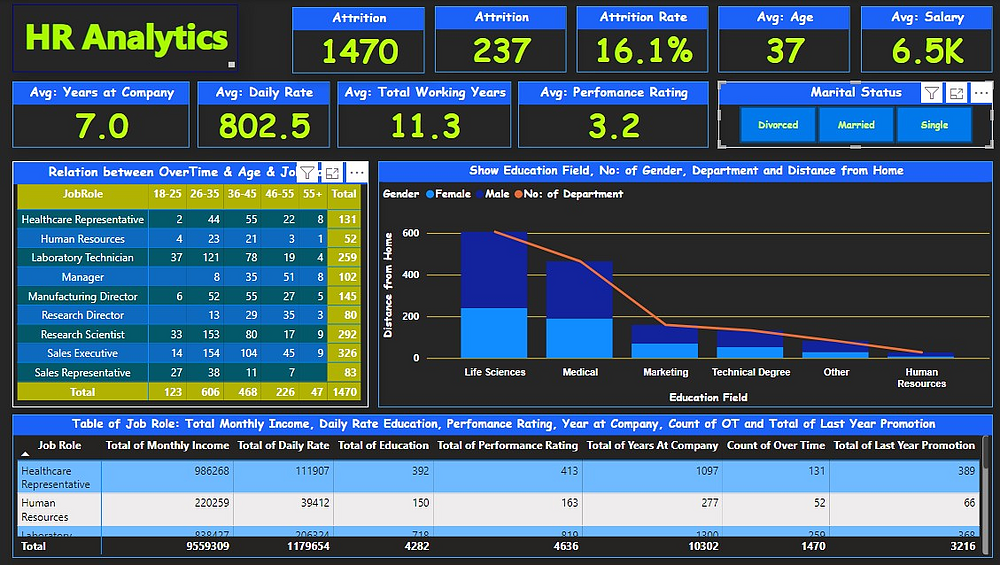
<div><h2 id="user-content-project-no-03-hr-analytics--power-bi" dir="auto" tabindex="-1">Project No# 08: HR Analytics | Power BI</h2>
<h3 id="user-content-project-no-3-hr-analytics--task-to-perform" dir="auto" tabindex="-1">Project No# 8: HR Analytics | Task to Perform</h3>
<ol dir="auto">
<li>Data Cleaning:</li>
</ol>
<ul dir="auto">
<li>Deleting redundant columns</li>
<li>Renaming the columns.</li>
<li>Dropping duplicates</li>
<li>Cleaning individual columns</li>
<li>Remove the NaN values from the dataset</li>
<li>Check for some more Transformations</li>
</ul>
<ol dir="auto" start="2">
<li>Data Visualization:</li>
</ol>
<ul dir="auto">
<li>Plot a correlation map for all numeric variables</li>
<li>Overtime</li>
<li>Marital Status</li>
<li>Job Role</li>
<li>Gender</li>
<li>Education Field</li>
<li>Department</li>
<li>Business Travel</li>
<li>Relation between Overtime and Age</li>
<li>Total Working Years</li>
<li>Education Level</li>
<li>Number of Companies Worked</li>
<li>Distance from Home</li>
</ul>
<h3 id="user-content-project-no-3-title-hr-analytics---data-cleaning-and-visualization" dir="auto" tabindex="-1">Project No 8: Title: HR Analytics - Data Cleaning and Visualization</h3>
<h4 id="user-content-project-description" dir="auto" tabindex="-1">Project Description:</h4>
<ul dir="auto">
<li>In the "HR Analytics" project, we will delve into the world of human resources data, focusing on data cleaning and visualization. The project's primary tasks encompass data preparation and creating informative data visualizations.</li>
</ul>
<h4 id="user-content-1-data-cleaning" dir="auto" tabindex="-1">1) Data Cleaning:</h4>
<ul dir="auto">
<li>Deleting Redundant Columns: We will begin by identifying and removing any redundant columns from the dataset that do not contribute to our analysis.</li>
<li>Column Renaming: To improve clarity, we will rename columns as needed, ensuring they are descriptive and meaningful.</li>
<li>Dropping Duplicates: Any duplicate entries in the dataset will be identified and removed to maintain data integrity.</li>
<li>Cleaning Individual Columns: We will perform data cleaning on individual columns to handle any inconsistencies, format issues, or outliers.</li>
<li>Removing NaN Values: To maintain data quality, we will address missing values by either imputing them or removing rows with missing data.</li>
<li>Additional Transformations: As necessary, we will conduct further data transformations to make the dataset more suitable for analysis.</li>
</ul>
<h4 id="user-content-2-data-visualization" dir="auto" tabindex="-1">2) Data Visualization:</h4>
<ul dir="auto">
<li>We will utilize Power BI to create insightful visualizations. The project's data visualizations will include:
<ul dir="auto">
<li>Correlation Map: A correlation map for all numeric variables to identify relationships among different HR metrics.</li>
<li>Overtime: Visualizing the impact of overtime on employee performance and retention.</li>
<li>Marital Status: Exploring the distribution of marital status among employees.</li>
<li>Job Role: Visualizing the distribution of employees across different job roles.</li>
<li>Gender: Analyzing gender diversity within the organization.</li>
<li>Education Field: Examining the educational backgrounds of employees in different fields.</li>
<li>Department: Visualizing the distribution of employees across various departments.</li>
<li>Business Travel: Understanding the extent of business travel and its impact on employee satisfaction and retention.</li>
<li>Relation between Overtime and Age: Investigating how age influences overtime work patterns.</li>
<li>Total Working Years: Analyzing the relationship between total working years and other factors.</li>
<li>Education Level: Visualizing the educational qualifications of employees.</li>
<li>Number of Companies Worked: Exploring how the number of companies worked at affects job satisfaction and retention.</li>
<li>Distance from Home: Visualizing the distance from home for employees.</li>
</ul>
</li>
</ul>
<h4 id="user-content-project-summary" dir="auto" tabindex="-1">Project Summary:</h4>
<ul dir="auto">
<li>The "HR Analytics - Data Cleaning and Visualization" project combines data cleaning and visualization to provide meaningful insights into human resources data. By ensuring data integrity through cleaning and presenting the data in a visually appealing manner, we aim to support informed HR decisions and improve understanding of workforce dynamics.</li>
<li>Through data visualization, we will uncover patterns and trends related to various HR metrics, enabling HR professionals to make data-driven decisions that impact employee satisfaction, retention, and overall organizational success. This project demonstrates the power of analytics in HR and its role in shaping organizational strategies.</li>
</ul></div>
<div><h2 id="user-content-title-project-no-02-diabetes-patients" dir="auto" tabindex="-1">Title Project No# 07: Diabetes Patients</h2>
<h3 id="user-content-problem-statement--project-no-02-diabetes-patients" dir="auto" tabindex="-1">Problem Statement | Project No# 07: Diabetes Patients</h3>
<ul dir="auto">
<li>This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases.</li>
<li>The objective of the dataset is to diagnostically predict whether a patient has diabetes based on certain diagnostic measurements included in the dataset. Several constraints were placed on the selection of these instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indian heritage.</li>
<li>From the data set in the (.csv) File We can find several variables, some of them are independent (several medical predictor variables) and only one target dependent variable (Outcome).</li>
</ul>
<h2 id="user-content-project-no-2-title-predicting-diabetes-in-pima-indian-patients-using-python" dir="auto" tabindex="-1">Project No 7: Title: Predicting Diabetes in Pima Indian Patients using Python | MeriSKILL</h2>
<ul dir="auto">
<li>The "Predicting Diabetes in Pima Indian Patients" project is aimed at developing a machine learning model that can predict the likelihood of diabetes in Pima Indian female patients who are at least 21 years old. This model uses diagnostic measurements to provide personalized predictions and assist in early diagnosis and preventive healthcare measures.</li>
</ul>
<h4 id="user-content-exploratory-data-analysis-eda" dir="auto" tabindex="-1">Exploratory Data Analysis (EDA):</h4>
<ul dir="auto">
<li>The project begins with an EDA to understand the dataset's characteristics and distribution. Visualizations, including histograms and scatterplots, offer insights into the distribution of variables like age, pregnancies, glucose, and insulin. The EDA also includes a correlation matrix heatmap to reveal relationships between variables.</li>
</ul>
<h4 id="user-content-data-preprocessing" dir="auto" tabindex="-1">Data Preprocessing:</h4>
<ul dir="auto">
<li>Feature scaling is applied to normalize the dataset, and the data is divided into training and testing sets. The choice of a Random Forest Classifier as the predictive model ensures robustness and reliability.</li>
</ul>
<h4 id="user-content-machine-learning-model" dir="auto" tabindex="-1">Machine Learning Model:</h4>
<ul dir="auto">
<li>The Random Forest Classifier is employed to predict diabetes. This ensemble learning technique excels in handling complex datasets, making it an excellent choice for this medical prediction task. The model's performance is evaluated using key metrics, including accuracy, precision, recall, and a confusion matrix.</li>
</ul>
<h4 id="user-content-user-interaction" dir="auto" tabindex="-1">User Interaction:</h4>
<ul dir="auto">
<li>One of the project's highlights is its interactive nature. A function is developed to allow users to input their medical predictor variables. The model then generates personalized predictions regarding the likelihood of diabetes. This interactive feature makes the project a valuable tool for personalized healthcare decision-making.</li>
</ul>
<h4 id="user-content-python-libraries" dir="auto" tabindex="-1">Python Libraries:</h4>
<ul dir="auto">
<li>Throughout the project, various Python libraries are utilized, including Numpy, Pandas, Matplotlib, Seaborn, and scikit-learn. These libraries streamline data analysis, visualization, preprocessing, and machine learning model development, making the code accessible and adaptable for broader healthcare applications.</li>
</ul>
<h4 id="user-content-summary" dir="auto" tabindex="-1">Summary:</h4>
<p dir="auto">In summary, the "Predicting Diabetes in Pima Indian Patients" Project is a compelling example of how data science and machine learning can be applied to address healthcare challenges. By leveraging diagnostic measurements, this project aids in the early detection of diabetes and empowers individuals with personalized risk assessments. It serves as a model for utilizing data-driven approaches to improve public health, particularly in populations with specific healthcare needs.</p>
</div>
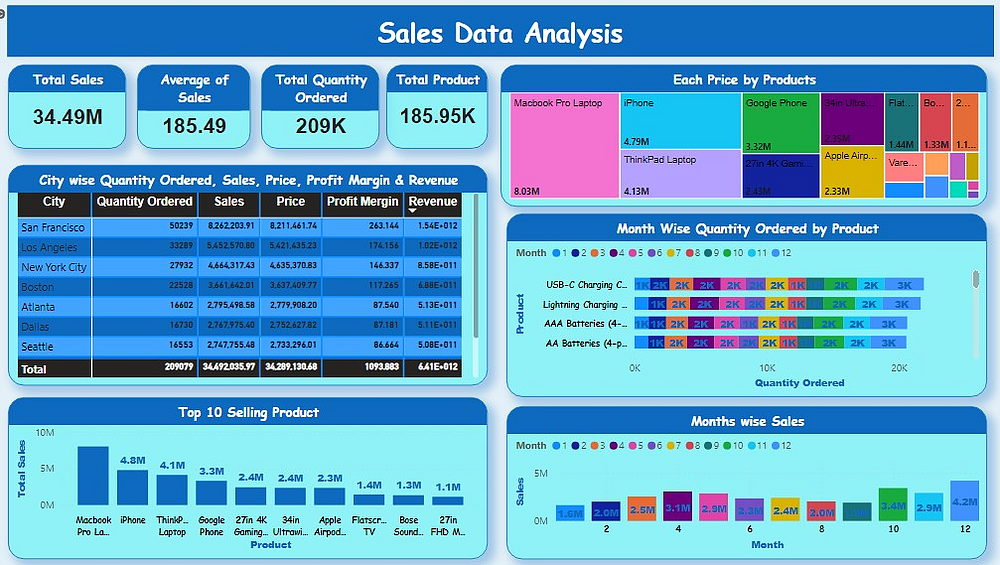
<div><h2 id="user-content-title-of-the-project-1-sales-data-analysis" dir="auto" tabindex="-1">Title of the Project 6: “Sales Data Analysis”</h2>
<h4 id="user-content-purpose" dir="auto" tabindex="-1">Purpose:</h4>
<ul dir="auto">
<li>Analyze sales data to identify trends, top-selling products, and revenue metrics for business decision-making.</li>
</ul>
<h4 id="user-content-description" dir="auto" tabindex="-1">Description:</h4>
<ul dir="auto">
<li>In this project, you will dive into a large sales dataset to extract valuable insights. You will explore sales trends over time, identify the best-selling products, calculate revenue metrics such as total sales and profit margins, and create visualizations to present your findings effectively. This project showcases your ability to manipulate and derive insights from large datasets, enabling you to make data-driven recommendations for optimizing sales strategies</li>
</ul>
<h3 id="user-content-project-1-sales-data-analysis--remote-internship--meriskill" dir="auto" tabindex="-1">Project 6: Sales Data Analysis | Remote Internship | MeriSKILL</h3>
<p dir="auto">This Power BI Sales Data Analysis 📊 project equips you with the skills and tools necessary to extract valuable insights from large datasets. By analyzing sales trends, identifying top-selling products, and calculating revenue metrics, you empower your organization to make informed, data-driven decisions. The interactive dashboard allows users to explore the data, while the provided recommendations offer clear guidance for optimizing sales strategies. In essence, this project demonstrates your proficiency in data manipulation and analysis, contributing to more effective business decisions and strategies.📊</p>
<h4 id="user-content-data-import-and-transformation" dir="auto" tabindex="-1">Data Import and Transformation:</h4>
<ul dir="auto">
<li>We start by importing and transforming the sales data to ensure it is ready for analysis.</li>
</ul>
<h4 id="user-content-sales-trends-analysis" dir="auto" tabindex="-1">Sales Trends Analysis:</h4>
<ul dir="auto">
<li>Utilizing Power BI's rich visualization capabilities, we delve into sales trends over time. This phase uncovers seasonality, growth patterns, and areas for potential improvement.</li>
</ul>
<h4 id="user-content-top-selling-products-identification" dir="auto" tabindex="-1">Top-Selling Products Identification:</h4>
<ul dir="auto">
<li>We determine the best-selling products, shedding light on which items are driving the most revenue, which can inform inventory management and marketing strategies.</li>
</ul>
<h4 id="user-content-revenue-metrics-calculation" dir="auto" tabindex="-1">Revenue Metrics Calculation:</h4>
<ul dir="auto">
<li>We calculate pivotal revenue metrics, including total sales and profit margins, to understand the financial performance of the business.</li>
</ul>
<h4 id="user-content-data-visualization" dir="auto" tabindex="-1">Data Visualization:</h4>
<ul dir="auto">
<li>A key strength of Power BI is its ability to create compelling data visualizations. We harness this to present our findings in an understandable and engaging manner.</li>
</ul>
<h4 id="user-content-data-driven-recommendations" dir="auto" tabindex="-1">Data-Driven Recommendations:</h4>
<ul dir="auto">
<li>Based on the insights derived from the analysis, we provide data-driven recommendations for optimizing sales strategies. These recommendations are grounded in the data, making them highly actionable.</li>
</ul>
<h4 id="user-content-interactive-dashboard-creation" dir="auto" tabindex="-1">Interactive Dashboard Creation:</h4>
<ul dir="auto">
<li>Central to our project is the development of an interactive Power BI dashboard. This dashboard serves as a user-friendly interface for exploring the data and comprehending the primary insights.</li>
</ul>
</div>
<div><h2 id="user-content-problem-statement--task-05--credit-card-fraud-detection-using-python" dir="auto" tabindex="-1">Problem Statement | Task 05 | Credit Card Fraud Detection USING PYTHON</h2>
<ul dir="auto">
<li>Build a machine learning model to identify fraudulent credit card transactions.</li>
<li>Preprocess and normalize the transaction data, handle class imbalance issues, and split the dataset into training and testing sets.</li>
<li>Train a classification algorithm, such as logistic regression or randomforests, to classify transactions as fraudulent or genuine.</li>
<li>Evaluate the model's performance using metrics like precision, recall, and F1-score, and consider techniques like oversampling or undersampling for improving results.</li>
</ul>
<h2 id="user-content-task-05-credit-card-fraud-detection-using-python" dir="auto" tabindex="-1">Task 05: Credit Card Fraud Detection Using Python</h2>
<p dir="auto">Credit card fraud is a significant concern in the financial industry, leading to substantial financial losses for individuals and organizations. Machine learning can play a crucial role in identifying fraudulent transactions. This project aims to build a machine learning model to detect credit card fraud using Python.</p>
<h3 id="user-content-importing-necessary-libraries" dir="auto" tabindex="-1">Importing Necessary Libraries:</h3>
<p dir="auto">We start by importing essential libraries such as NumPy, Pandas, Matplotlib, Seaborn, and scikit-learn. These libraries provide tools for data analysis, visualization, and machine learning.</p>
<h3 id="user-content-loading-the-dataset" dir="auto" tabindex="-1">Loading the Dataset:</h3>
<p dir="auto">We load the Credit Card Fraud Detection dataset (creditcard.csv) using Pandas. The dataset contains transaction data, including features like time, amount, and class (0 for genuine transactions and 1 for fraudulent transactions).</p>
<h3 id="user-content-exploratory-data-analysis-eda" dir="auto" tabindex="-1">Exploratory Data Analysis (EDA):</h3>
<p dir="auto">We perform EDA to understand the dataset better.</p>
<ul dir="auto">
<li>We display basic dataset information, including data types and the number of rows and columns.</li>
<li>We provide a statistical summary of the dataset.</li>
<li>We check for missing values and visualize them using a heatmap.</li>
<li>We create a scatter plot to visualize the relationship between time, amount, and fraud class.</li>
</ul>
<h3 id="user-content-data-preprocessing-3" dir="auto" tabindex="-1">Data Preprocessing:</h3>
<p dir="auto">Data preprocessing is essential to prepare the dataset for machine learning.</p>
<ul dir="auto">
<li>We normalize and scale the 'Amount' and 'Time' features using StandardScaler.</li>
<li>We split the data into features (X) and the target variable (y) where 'Class' is the target.</li>
<li>The dataset is further split into training and testing sets (80% training and 20% testing) using train_test_split.</li>
</ul>
<h3 id="user-content-model-training-and-evaluation-3" dir="auto" tabindex="-1">Model Training and Evaluation:</h3>
<ul dir="auto">
<li>We train a Logistic Regression model on the training data.</li>
<li>The trained model is used to make predictions on the testing data.</li>
<li>We evaluate the model's performance using various metrics:
<ul dir="auto">
<li>Accuracy: Measures the overall correctness of predictions.</li>
<li>Precision: Measures the proportion of true positive predictions among all positive predictions.</li>
<li>Recall: Measures the proportion of true positive predictions among all actual positives.</li>
<li>F1 Score: Combines precision and recall to provide a balanced measure.</li>
<li>Confusion Matrix: Shows the counts of true positive, true negative, false positive, and false negative predictions.</li>
</ul>
</li>
<li>We provide a detailed classification report with precision, recall, and F1-score for both genuine and fraudulent transactions.</li>
</ul>
<h3 id="user-content-conclusion-4" dir="auto" tabindex="-1">Conclusion:</h3>
<p dir="auto">Credit Card Fraud Detection is a critical application of machine learning, helping financial institutions protect their customers from fraud. This Python project showcases the entire process, from data exploration and preprocessing to model training and evaluation. Building robust fraud detection models is vital for maintaining trust and security in financial transactions.</p>
<p dir="auto">Thank you for joining us on this journey through Credit Card Fraud Detection with Python!</p></div>
<div><h2 id="user-content-problem-statement--task-4--sales-prediction-using-python" dir="auto" tabindex="-1">Problem Statement | Task 4 | SALES PREDICTION USING PYTHON</h2>
<ul dir="auto">
<li>
<p dir="auto">Sales prediction involves forecasting the amount of a product that customers will purchase, taking into account various factors such as advertising expenditure, target audience segmentation, and advertising platform selection.</p>
</li>
<li>
<p dir="auto">In businesses that offer products or services, the role of a Data Scientist is crucial for predicting future sales. They utilize machine learning techniques in Python to analyze and interpret data, allowing them to make informed decisions regarding advertising costs. By leveraging these predictions, businesses can optimize their advertising strategies and maximize sales potential. Let's embark on the journey of sales prediction using machine learning in Python.</p>
</li>
</ul>
<h2 id="user-content-task-04-sales-prediction-using-python" dir="auto" tabindex="-1">Task 04: Sales Prediction Using Python</h2>
<p dir="auto">Sales prediction is a critical task for businesses, allowing them to make informed decisions regarding advertising expenditure and strategies. In this project, we leverage Python and machine learning techniques to predict sales based on advertising spending on TV, radio, and newspapers. This project demonstrates how data analysis and linear regression can optimize advertising budgets.</p>
<h3 id="user-content-python-libraries-used" dir="auto" tabindex="-1">Python Libraries Used:</h3>
<ol dir="auto">
<li>numpy: For numerical operations and calculations.</li>
<li>pandas: For data manipulation and analysis.</li>
<li>matplotlib: For data visualization.</li>
<li>seaborn: For advanced data visualization.</li>
<li>sklearn: For machine learning tasks, including model training and evaluation.</li>
</ol>
<h3 id="user-content-data-exploration-1" dir="auto" tabindex="-1">Data Exploration:</h3>
<ul dir="auto">
<li>The project begins with data exploration, where we load and analyze the dataset.</li>
<li>We examine the dataset's structure, summary statistics, and relationships between variables.</li>
<li>Data visualization is used to gain insights into the count of sales, average sales per advertising channel, and more.</li>
</ul>
<h3 id="user-content-correlation-analysis" dir="auto" tabindex="-1">Correlation Analysis:</h3>
<ul dir="auto">
<li>We employ a heatmap to visualize the correlation matrix of the dataset.</li>
<li>This analysis reveals how different advertising channels correlate with sales.</li>
<li>It guides us in understanding which advertising mediums have the most impact on sales.</li>
</ul>
<h3 id="user-content-data-preprocessing-2" dir="auto" tabindex="-1">Data Preprocessing:</h3>
<ul dir="auto">
<li>Data preprocessing involves handling missing values and preparing data for machine learning.</li>
<li>In this project, there are no missing values to handle, so we proceed with feature selection.</li>
</ul>
<h3 id="user-content-model-training-and-evaluation-2" dir="auto" tabindex="-1">Model Training and Evaluation:</h3>
<ul dir="auto">
<li>We split the dataset into features (advertising expenditures) and the target variable (sales).</li>
<li>A Linear Regression model is selected for sales prediction.</li>
<li>The model is trained on the training data and evaluated using Mean Squared Error and R-squared.</li>
<li>A scatter plot illustrates the relationship between actual sales and predicted sales.</li>
</ul>
<h3 id="user-content-sales-prediction" dir="auto" tabindex="-1">Sales Prediction:</h3>
<ul dir="auto">
<li>The trained model is now ready for making predictions.</li>
<li>Users can input new advertising spending scenarios, and the model predicts sales based on the provided inputs.</li>
</ul>
<h3 id="user-content-conclusion-3" dir="auto" tabindex="-1">Conclusion:</h3>
<p dir="auto">Sales prediction using Python and machine learning allows businesses to optimize their advertising strategies. By understanding the impact of different advertising channels on sales, companies can make data-driven decisions to maximize their revenue. This project showcases the power of Python libraries for data analysis and prediction in the business domain.</p>
<p dir="auto">Thank you for joining us on this journey through Sales Prediction with Python!</p></div>
<div><h2 id="user-content-problem-statement--task-3--iris-flower-classification" dir="auto" tabindex="-1">Problem Statement | Task 3 | IRIS Flower Classification</h2>
<ul dir="auto">
<li>
<p dir="auto">The Iris flower dataset consists of three species: setosa, versicolor,and virginica. These species can be distinguished based on their measurements. Now, imagine that you have the measurements of Iris flowers categorized by their respective species. Your objective is to train a machine learning model that can learn fromthese measurements and accurately classify the Iris flowers into their respective species.</p>
</li>
<li>
<p dir="auto">Use the Iris dataset to develop a model that can classify iris flowers into different species based on their sepal and petal measurements. This dataset is widely used for introductory classification tasks.</p>
</li>
</ul>
<h2 id="user-content-task-3-title-iris-flower-classification-with-python" dir="auto" tabindex="-1">Task 3: Title: IRIS Flower Classification with Python</h2>
<p dir="auto">The project title is "IRIS Flower Classification with Python." The objective is to build a machine learning model that accurately classifies Iris flowers into their respective species based on sepal and petal measurements. We'll use various Python libraries to explore the Iris dataset, visualize the data, preprocess it, train a logistic regression model, evaluate its performance, and make predictions.</p>
<h3 id="user-content-dataset-exploration" dir="auto" tabindex="-1">Dataset Exploration:</h3>
<p dir="auto">We start by loading the Iris dataset and conducting preliminary exploratory data analysis. We check the dataset's dimensions, information, and summary statistics to understand its structure.</p>
<h3 id="user-content-data-visualization" dir="auto" tabindex="-1">Data Visualization:</h3>
<p dir="auto">Data visualization is crucial in understanding the relationships within the dataset. We use seaborn and matplotlib to create pair plots, count plots, histograms, and other visualizations to reveal patterns and insights. The pair plot shows how different species are distributed based on sepal and petal measurements.</p>
<h3 id="user-content-data-pre-processing" dir="auto" tabindex="-1">Data Pre-processing:</h3>
<p dir="auto">Before training the model, we preprocess the data. We split the dataset into features (X) and target (y). Then, we split it into training and testing sets to assess the model's performance.</p>
<h3 id="user-content-model-training-and-evaluation-1" dir="auto" tabindex="-1">Model Training and Evaluation:</h3>
<p dir="auto">We select a logistic regression model for this classification task. We train the model on the training data and evaluate its performance using metrics like accuracy, confusion matrix, and classification report. The model shows high accuracy in classifying Iris species.</p>
<h3 id="user-content-making-predictions" dir="auto" tabindex="-1">Making Predictions:</h3>
<p dir="auto">To demonstrate the model's utility, we make predictions on a sample data point with sepal and petal measurements. The model successfully predicts the species of the given data.</p>
<h3 id="user-content-future-directions-2" dir="auto" tabindex="-1">Future Directions:</h3>
<p dir="auto">In future iterations of this project, we can explore other classification algorithms, perform hyperparameter tuning, and implement cross-validation for more robust model evaluation. Additionally, deploying the model as a web application or integrating it into a larger ecosystem can be considered.</p>
<h3 id="user-content-conclusion-2" dir="auto" tabindex="-1">Conclusion:</h3>
<p dir="auto">In conclusion, the Iris Flower Classification project showcases the power of Python libraries for data analysis, visualization, and machine learning. The model accurately classifies Iris flowers into species based on their measurements, demonstrating the practicality of machine learning in real-world classification tasks.</p>
<p dir="auto">Thank you for joining us on this journey through movie rating prediction with Python!</p></div>
<div><h2 id="user-content-problem-statement--task-2--movie-rating-prediction-with-python" dir="auto" tabindex="-1">Problem Statement | Task 2 | MOVIE RATING PREDICTION WITH PYTHON</h2>
<ul dir="auto">
<li>
<p dir="auto">Build a model that predicts the rating of a movie based on features like genre, director, and actors. You can use regression techniques to tackle this problem.</p>
</li>
<li>
<p dir="auto">The goal is to analyze historical movie data and develop a model that accurately estimates the rating given to a movie by users or critics.</p>
</li>
<li>
<p dir="auto">Movie Rating Prediction project enables you to explore data analysis, preprocessing, feature engineering, and machine learning modeling techniques. It provides insights into the factors that influence movie ratings and allows you to build a model that can estimate the ratings of movies accurately.</p>
</li>
</ul>
<h2 id="user-content-task-2-title-movie-rating-prediction-with-python" dir="auto" tabindex="-1">Task 2: Title: Movie Rating Prediction with Python</h2>
<p dir="auto">Welcome to the Movie Rating Prediction project, where we harness the power of Python and its libraries to analyze and predict movie ratings. We dive into the IMDbMoviesIndia dataset, exploring its features and conducting data preprocessing, visualization, and model building to forecast movie ratings.</p>
<h3 id="user-content-python-libraries-utilized" dir="auto" tabindex="-1">Python Libraries Utilized</h3>
<p dir="auto">numpy for numerical operations. pandas for data manipulation and analysis. seaborn and matplotlib for data visualization. sklearn for model selection, data splitting, and evaluation. LinearRegression for building the predictive model. mean_squared_error for model evaluation.</p>
<h3 id="user-content-data-exploration" dir="auto" tabindex="-1">Data Exploration</h3>
<p dir="auto">We commence with data exploration:</p>
<p dir="auto">Checking for missing values reveals that we have some. Visualization of missing data is presented via a heatmap. Duplicate data is checked and removed. We convert data types for 'Votes,' 'Year,' and 'Duration' to the appropriate numeric formats.</p>
<h3 id="user-content-analysis-and-visualization" dir="auto" tabindex="-1">Analysis and Visualization</h3>
<p dir="auto">We analyze the dataset, finding the movie with a runtime of 120 minutes or more. The year with the highest average voting is identified. Visualizations, such as a bar plot showcasing the number of movies per year and a heatmap to explore correlations, are presented.</p>
<h3 id="user-content-data-preprocessing-1" dir="auto" tabindex="-1">Data Preprocessing</h3>
<p dir="auto">Unnecessary columns like 'Name,' 'Genre,' 'Actor 1,' 'Actor 2,' 'Actor 3,' and 'Director' are dropped. Data is split into training and testing sets.</p>
<h3 id="user-content-model-building-and-evaluation" dir="auto" tabindex="-1">Model Building and Evaluation</h3>
<p dir="auto">We opt for a linear regression model for rating prediction. The model is trained and evaluated using the root mean squared error (RMSE). Predictions are made for movie ratings.</p>
<h3 id="user-content-future-directions-1" dir="auto" tabindex="-1">Future Directions</h3>
<p dir="auto">In the future, we can enhance this project by incorporating more advanced machine learning techniques, feature engineering, and exploring other datasets to improve prediction accuracy. Moreover, user interfaces could be developed to make rating predictions more user-friendly.</p>
<h3 id="user-content-conclusion-1" dir="auto" tabindex="-1">Conclusion</h3>
<p dir="auto">The Movie Rating Prediction project showcases the capabilities of Python in data analysis and predictive modeling. By leveraging various libraries and techniques, we have demonstrated how to forecast movie ratings based on key attributes, opening doors to further enhancements and applications in the realm of movie recommendations and analysis.</p>
<p dir="auto">Thank you for joining us on this journey through movie rating prediction with Python!</p></div>
<div><h2 id="user-content-problem-statement" dir="auto" tabindex="-1">Problem Statement</h2>
<h2 id="user-content-task-1--titanic-survival-prediction" dir="auto" tabindex="-1">Task 1 | TITANIC SURVIVAL PREDICTION</h2>
<ul dir="auto">
<li>
<p dir="auto">Use the Titanic dataset to build a model that predicts whether a passenger on the Titanic survived or not. This is a classic beginner project with readily available data.</p>
</li>
<li>
<p dir="auto">The dataset typically used for this project contains information about individual passengers, such as their age, gender, ticket class, fare, cabin, and whether or not they survived.</p>
</li>
</ul>
<h3 id="user-content-introduction" dir="auto" tabindex="-1">Introduction:</h3>
<p dir="auto">Our Titanic Survival Prediction project employs machine learning to predict passenger survival on the Titanic. This beginner-level project utilizes the Titanic dataset, encompassing details such as age, gender, ticket class, fare, cabin, and survival status.</p>
<h3 id="user-content-data-exploration-and-analysis" dir="auto" tabindex="-1">Data Exploration and Analysis:</h3>
<p dir="auto">We began by exploring and visualizing the data. Notable insights include:</p>
<p dir="auto">The majority did not survive (0: Died, 1: Survived). Age distribution revealed a range of passenger ages. Male passengers outnumbered females. Fare distribution exhibited varying ticket prices. Most passengers belonged to the third ticket class (Pclass).</p>
<h3 id="user-content-data-preprocessing" dir="auto" tabindex="-1">Data Preprocessing:</h3>
<p dir="auto">We prepared the data by:</p>
<p dir="auto">Removing unnecessary columns, such as 'Name', 'Ticket', 'PassengerId', 'Parch', and 'Cabin.' Handling missing values in 'Age' and 'Embarked.' Encoding categorical variables 'Sex' and 'Embarked.'</p>
<h3 id="user-content-model-training-and-evaluation" dir="auto" tabindex="-1">Model Training and Evaluation:</h3>
<p dir="auto">We used logistic regression to build our predictive model. After splitting the data into training and testing sets, our model achieved an accuracy of [insert accuracy percentage].</p>
<h3 id="user-content-conclusion" dir="auto" tabindex="-1">Conclusion:</h3>
<p dir="auto">In conclusion, our Titanic Survival Prediction project demonstrated the application of machine learning and data analysis. We visualized key insights, preprocessed the data, and successfully predicted passenger survival. The model's accuracy reflects its effectiveness in binary classification.</p>
<h3 id="user-content-future-directions" dir="auto" tabindex="-1">Future Directions:</h3>
<p dir="auto">Future work may involve exploring other machine learning algorithms, fine-tuning hyperparameters, and expanding feature engineering.</p>
<p dir="auto">Thank you for your attention. This project offers a practical example of data analysis, data science and machine learning in action.</p></div>
سرورق تبدیل کریں
زوم:
Beware! Reported Companies
Rozee.pk is not in business with below-mentioned companies due to multiple fraudulent recruiting
complaints/activities which begun with fictitious interview inquiries sent by instant message (IM), email, or
text. If the employer asks you to pay money for any purpose including processing to shortlisting, please
immediately report at support@rozee.pk.
Dewan Global
SA Parco Group of Companies
Crystal Group of Companies
Advance Superior Group USA
Techium Solution
Royal Indus Group
Pak Adam Group
Day & Night Recruitment Agency
Umair Property Marketing
Easysearch.pk
Saigol Group of Companies
Pak United Arab Group
Supreme Group of Companies
HA Group of Companies
Etihad Group of Companies
KP Group of Companies
Vital Group of Companies
AR Enterprises
Delta Group of Companies
Ultimate HR Solution
World International LLC
AJL Group of Companies
Bestland Group
Bizlinks
Lexer Group of Companies
Fragrance Land Pvt Ltd
Khawaja Group of Industries
EBS (Earn Be Smart) Pvt Ltd
Jamal Group of Industries
Jamal Mirza Group of Company
Pro Hirez
Kwality Surgical
Kwality Group
Easy Search Pvt Ltd
Shah International Technical Training Institute & Consultants Pvt Ltd